OpenAI가 내부에서 사용하는 데이터 에이전트에 대한 글을 공개했습니다. 600+ 페타바이트라는 숫자는 처음 접해보네요 🫢
저희 내부에서도 SQL bot을 만들어 활용하고 있지만, 이 정도 규모의 데이터를 다루는 환경에서는 단순히 쿼리를 잘 돌리는 것만으로는 부족하겠다는 생각이 들었습니다.
OpenAI가 이 문제를 어떤 방식으로 풀었는지 정리해봤습니다.
⸻
👾 데이터는 충분했지만, 답은 느렸다
이미 충분한 데이터가 쌓여 있었습니다. 사용자 행동 로그, 실험 결과, 모델 평가 데이터까지 규모의 문제는 아니었습니다. 문제는 질문에서 답까지 이어지는 과정이었습니다.
현업에서 나온 질문은 데이터 팀을 거쳐야 했고, 결과가 다시 돌아올 때쯤이면 맥락이 흐려지는 경우도 많았습니다. 무엇을 알고 싶었는지보다 어떤 쿼리를 돌릴 수 있는지가 앞서는 순간도 생겼습니다. 데이터는 존재했지만 조직 전체가 데이터를 통해 빠르게 사고한다고 보기는 어려운 구조였다고 합니다.
⸻
💡 OpenAI가 선택한 해법
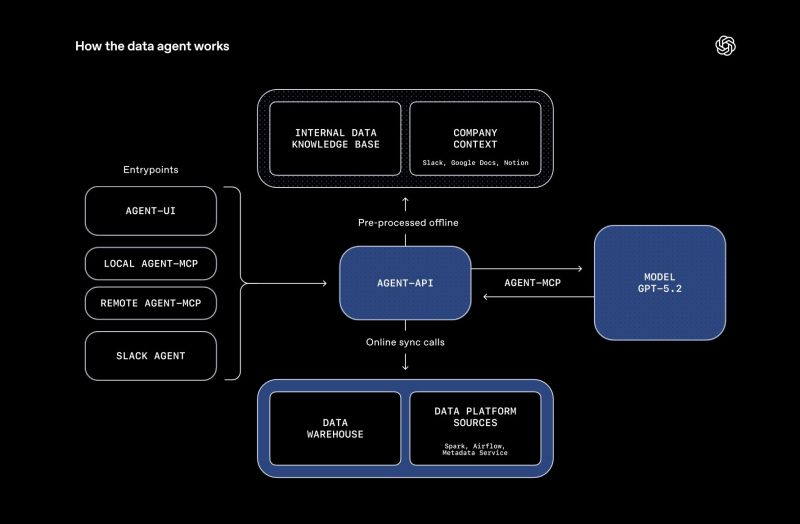
데이터 에이전트는 단순 분석 도구가 아니라 질문의 흐름을 하나로 연결하는 역할에 가깝습니다. 에이전트는 질문을 그대로 실행하지 않습니다. 먼저 의도를 정리하고, 어떤 데이터가 필요한지 구조화한 뒤 쿼리를 생성합니다. 그리고 결과를 숫자 그대로 전달하는 대신 사람이 이해할 수 있는 언어로 요약한다고 합니다.
질문, 실행, 해석이 하나의 흐름으로 묶이면서 중간에 맥락이 끊기지 않도록 설계되어 있습니다. 제품, 연구, 운영 팀도 스스로 데이터를 탐색할 수 있게 되었고 데이터는 요청의 대상이 아니라 사고의 출발점이 되기 시작했습니다.
⸻
💬 빠른 답보다 올바른 질문
인상 깊었던 부분은 속도에 대한 태도였습니다. 에이전트는 애매한 질문에 바로 답하지 않습니다(👍👍👍). 의도가 불분명하면 되묻고 여러 해석이 가능하면 선택지를 제시합니다. 빠르게 실행하는 대신, 질문을 명확히 만드는 데 시간을 씁니다.
또한 모든 결과에는 사용된 데이터와 가정이 함께 남습니다. 덕분에 결과를 그대로 받아들이기보다 검증하고 토론할 수 있는 상태가 됩니다. 분석 속도를 높이기 위한 장치라기보다, 신뢰 가능한 의사결정을 위한 설계에 가깝다고 느껴졌습니다.
⸻
원문 글은 600+ 페타바이트 데이터를 처리하는 방법을 알려주기 보다, 조직이 데이터를 어떻게 사고의 재료로 쓰는지를 보여주는 것 같습니다.