AI 많이 사용하고 계시죠? 아마 많이 활용하시는 분들은 폴더와 파일 관리의 중요성을 누구보다 잘 알고 계실 것 같습니다. 만약 여러분의 .md 파일이 하나의 폴더 안에 a.md, a-final.md, a-final-final.md 같은 이름으로 계속 쌓여 있다면 어떨까요?
파일은 계속 늘어나지만 어떤 내용이 어디 있는지 점점 알기 어려워집니다. 결국 파일은 많지만 찾기도 어렵고 활용하기도 어려운 상태가 됩니다.
데이터도 마찬가지입니다.
데이터가 많아질수록 구조 없이 쌓이기만 하면 분석은 점점 어려워지고, 분석 결과를 신뢰하기도 어려워집니다. Amplitude는 이 문제의 핵심 원인을 이벤트 분류 체계(Event Taxonomy)에서 찾습니다.
제품 데이터가 늘어날수록 이벤트 구조가 정리되어 있지 않으면 분석은 점점 더 복잡해지고, 결국 데이터를 이해하기 어려운 상태가 된다는 이야기입니다.
⸻
이벤트가 늘어날수록 분석은 복잡해집니다
제품이 성장하면 이벤트도 빠르게 늘어납니다. 기능이 추가되고 팀이 늘어나고 데이터 활용이 많아질수록 각 팀은 필요에 따라 새로운 이벤트를 만듭니다. 문제는 기준 없이 만들어질 때입니다.
같은 행동을 기록하는 이벤트가 여러 개 존재
이벤트 이름이 제각각
어떤 이벤트를 사용해야 할지 모름
이벤트 의미가 문서화되지 않음
마치 폴더 구조 없이 파일이 계속 쌓이는 상황과 같습니다. 그리고 이 문제는 AI로 데이터를 분석할 때 더 크게 드러납니다.💣
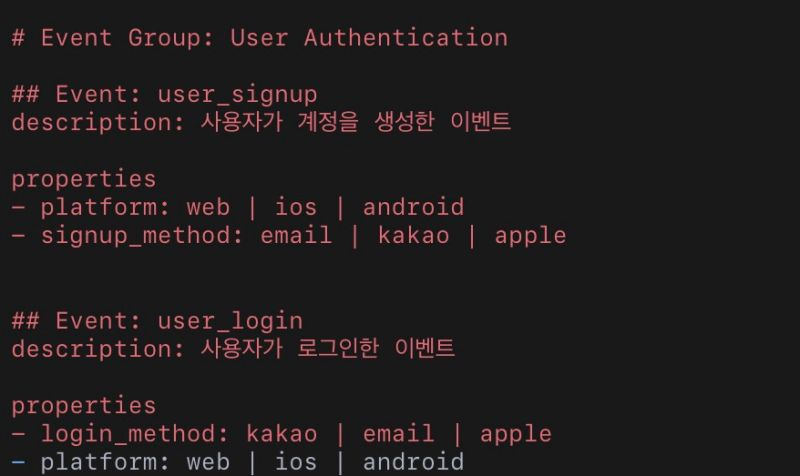
이벤트 이름이 데이터 이해도를 결정합니다
이벤트 구조에서 가장 기본은 이벤트 네이밍 규칙입니다. 이벤트 이름은 데이터를 이해하는 언어이기 때문입니다. 예를 들어 같은 행동을 기록하는 이벤트가 아래처럼 존재할 수 있습니다.
file_export
export_file
download_file
모두 같은 행동이지만 분석에서는 서로 다른 이벤트로 인식됩니다. 그래서 이벤트는 사용자 행동이 명확하게 드러나는 방식으로 정의되어야 합니다.
이벤트는 관리 구조가 필요합니다
이벤트가 많아지면 기억만으로는 관리가 어렵습니다. 그래서 필요한 것이 Event Taxonomy입니다. 예를 들면 다음과 같은 기준입니다.
이벤트 네이밍 규칙
이벤트 설명 문서
이벤트 속성 정의
이벤트 생성 기준
이런 기준이 있어야 데이터가 지속적으로 이해 가능한 구조로 유지됩니다.
⸻
데이터 분석 문제는 데이터 부족으로 보이지만, 사실 데이터 구조 문제인 경우가 더 많으니 체계를 잡는데 집중해보세요🙌